Abdullah Akgül
PhD, Reinforcement Learning · University of Southern Denmark

🔍 Open to Research Scientist & MLE roles
Formerly ADIN Lab · Denmark
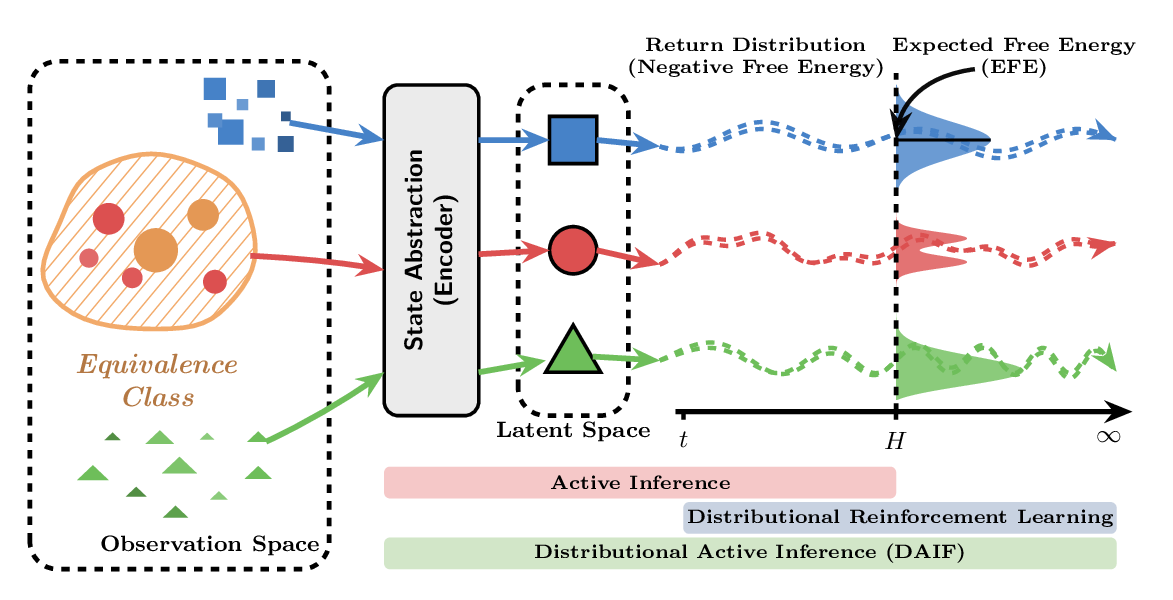
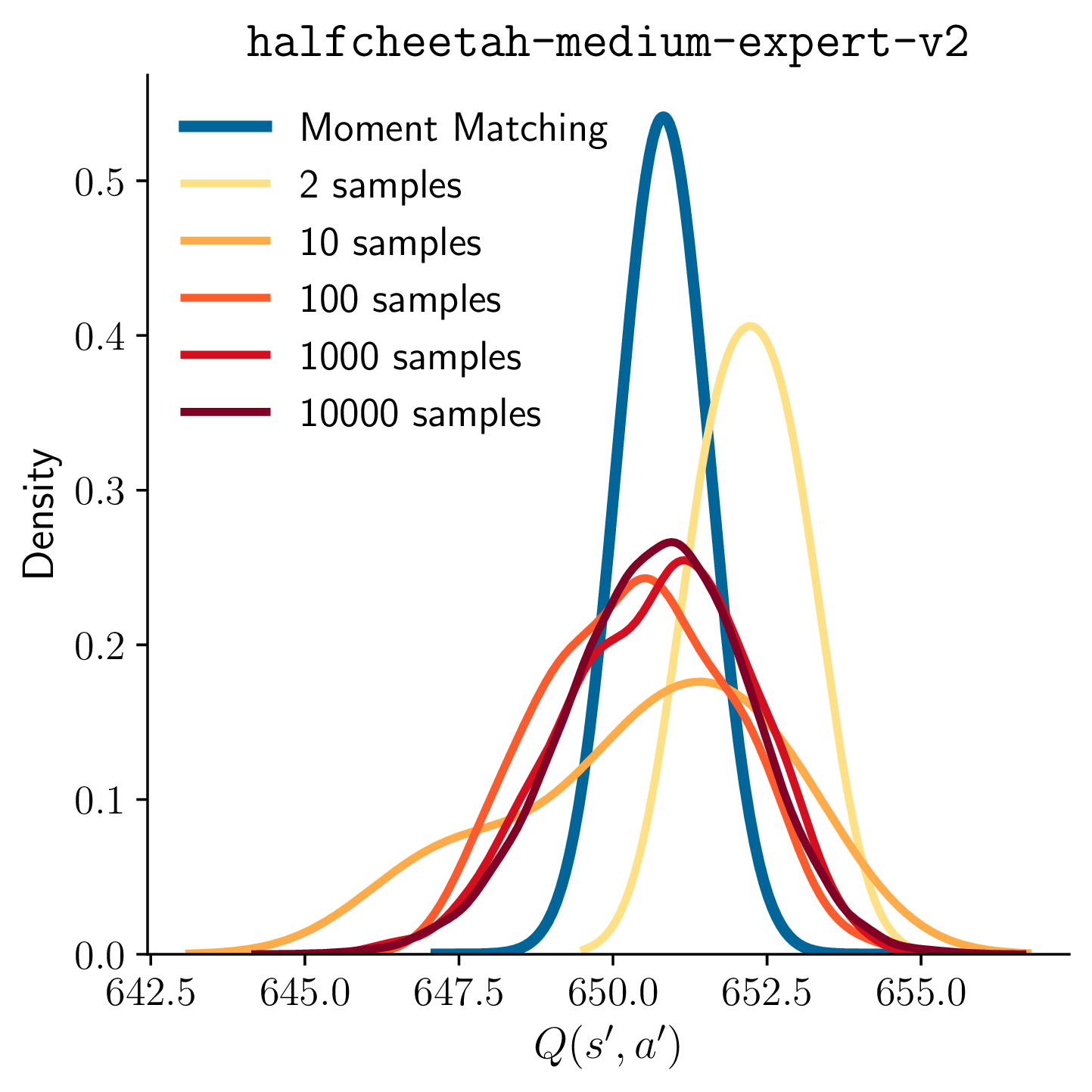
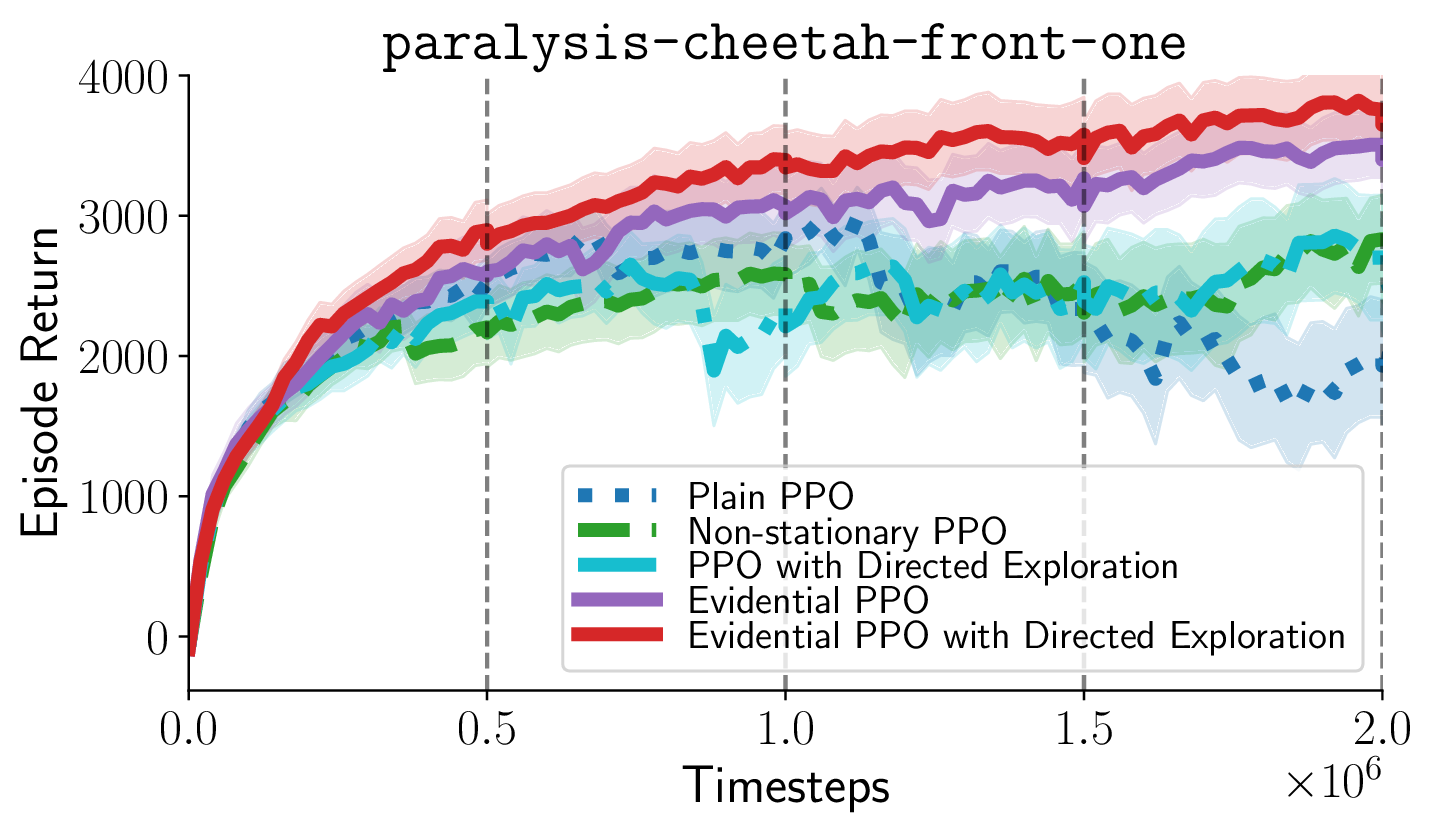
I build probabilistic algorithms that make reinforcement learning agents learn faster by treating uncertainty as a signal rather than noise. I am a machine learning researcher. Three of my algorithms — MOMBO on offline RL, EPPO on non-stationary control, and DAIF on online control — rank first in sample efficiency on their respective benchmarks, with publications at NeurIPS, ICML, ICLR, and TMLR.
My background spans industry deployment, probabilistic modeling, and reinforcement learning. Before my PhD, I built a fraud detection system using deep metric learning at Vakifbank, and published on federated Bayesian networks, uncertainty quantification, and continual learning of dynamical systems. Across all of it, the same question recurs: how should a model represent what it does not know, and how should that uncertainty shape its decisions? My PhD focuses that question on reinforcement learning across three settings: offline learning from fixed datasets, rapid adaptation to non-stationary dynamics, and sample-efficient online exploration, where probabilistic representations consistently prove to be the decisive ingredient.
I am actively looking for research scientist or machine learning engineer roles in industry, where I can apply these methods to real-world sequential decision-making, robotics, and autonomous systems problems. Beyond research, I contribute open-source codebases (ObjectRL, MOMBO, EPPO) adopted by the research community, serve as a reviewer for NeurIPS, TNNLS, WACV, and EWRL, and have mentored MSc students whose work led to publications at TMLR and NeurIPS.
news
| Jun 01, 2026 | Paper “Weighted Sequential Bayesian Inference for Non-Stationary Linear Contextual Bandits” accepted to UAI 2026 (Conference on Uncertainty in Artificial Intelligence). |
|---|---|
| May 18, 2026 | Successfully defended PhD thesis Probabilistic Reinforcement Learning for Sample-Efficient Control at the University of Southern Denmark. |
| Apr 30, 2026 | Paper DAIF “Distributional Active Inference” accepted to ICML 2026. |
| Feb 01, 2026 | Started as Research Assistant – Postdoctoral Researcher at the University of Southern Denmark, continuing research on probabilistic reinforcement learning for sample-efficient control. |
| Jan 26, 2026 | Paper iS-QL “Bridging the Performance-Gap between Target-free and Target-based Reinforcement Learning” accepted to ICLR 2026. |
highlights