Publications
Peer-reviewed publications in reinforcement learning, probabilistic modeling, and uncertainty quantification.
2026
- Ph.D. Thesis
 Probabilistic Reinforcement Learning for Sample-Efficient ControlA. Akgül2026
Probabilistic Reinforcement Learning for Sample-Efficient ControlA. Akgül2026@article{akgul2026probabilistic, title = {Probabilistic Reinforcement Learning for Sample-Efficient Control}, author = {Akg{\"u}l, A.}, year = {2026}, url = {https://portal.findresearcher.sdu.dk/en/publications/probabilistic-reinforcement-learning-for-sample-efficient-control/}, project = {/projects/phdthesis.html}, } - arXivHitting Time Isomorphism for Multi-Stage Planning with Foundation PoliciesM. V. Boock, A. Akgül, M. M. Çelikok, and M. KandemirarXiv Preprint, 2026
We present a new operator-theoretic representation learning framework for offlinereinforcement learning that recovers the directed temporal geometry of a controlledMarkov process from hitting time observations. While prior art often producessymmetric distances or fails to satisfy the triangle inequality, our framework learns a Hilbert-space displacement geometry where expected hitting times are realized as linear functionals of latent displacements. We prove that this representation exists under latent linear closure and is uniquely identifiable up to a bounded linear isomorphism. For finite-dimensional implementations, we show that global hitting-time error is bounded by one-step transition error amplified by the environment’s transient spectral radius. Furthermore, we provide finite-sample guarantees accounting for approximation, statistical complexity, and trajectory-label mismatch. Derived from this theory, we curate Isomorphic Embedding Learning (IEL) as a new goal-agnostic foundation policy learning algorithm that anchors a HILP-style consistency objective with explicit hitting-time regression to ensure that the learned geometry reflects actual decision-time progress. This asymmetric and compositional structure enables robust graph-based multi-stage planning for long-horizon navigation. Our experiments demonstrate that IEL improves the state of the art of learning foundation policy policies from offline maze locomotion data. Our code can be found at https://github.com/MagnusBoock/IEL
@article{boock2026hittingtime, title = {Hitting Time Isomorphism for Multi-Stage Planning with Foundation Policies}, author = {Boock, M. V. and Akg{\"u}l, A. and {\c{C}}elikok, M. M. and Kandemir, M.}, year = {2026}, journal = {arXiv Preprint}, url = {https://arxiv.org/pdf/2605.06470}, } - ICLR
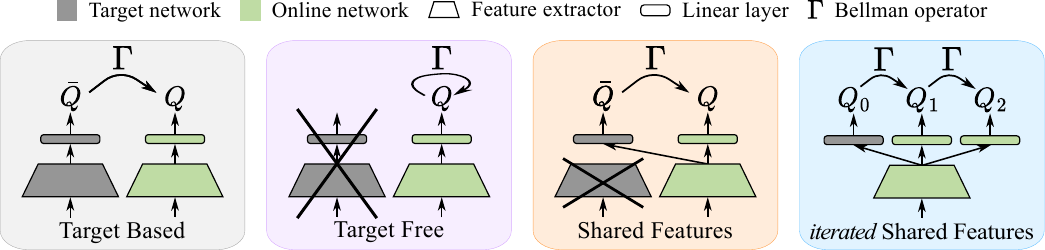 Bridging the performance-gap between target-free and target-based reinforcement learningT. Vincent, Y. Tripathi, T. Faust, A. Akgül, and 4 more authorsIn International Conference on Learning Representations, 2026
Bridging the performance-gap between target-free and target-based reinforcement learningT. Vincent, Y. Tripathi, T. Faust, A. Akgül, and 4 more authorsIn International Conference on Learning Representations, 2026The use of target networks in deep reinforcement learning is a widely popular solution to mitigate the brittleness of semi-gradient approaches and stabilize learning. However, target networks notoriously require additional memory and delay the propagation of Bellman updates compared to an ideal target-free approach. In this work, we step out of the binary choice between target-free and target-based algorithms. We introduce a new method that uses a copy of the last linear layer of the online network as a target network, while sharing the remaining parameters with the up-to-date online network. This simple modification enables us to keep the target-free’s low-memory footprint while leveraging the target-based literature. We find that combining our approach with the concept of iterated Q-learning, which consists of learning consecutive Bellman updates in parallel, helps improve the sample-efficiency of target-free approaches. Our proposed method, iterated Shared Q-Learning (iS-QL), bridges the performance gap between target-free and target-based approaches across various problems while using a single Q-network, thus stepping towards resource-efficient reinforcement learning algorithms.
@inproceedings{vincent2026bridging, title = {Bridging the performance-gap between target-free and target-based reinforcement learning}, author = {Vincent, T. and Tripathi, Y. and Faust, T. and Akg{\"u}l, A. and Oren, Y. and Kandemir, M. and Peters, P. and D'Eramo, C.}, booktitle = {International Conference on Learning Representations}, year = {2026}, url = {https://openreview.net/pdf?id=ltcxS7JE0c}, project = {/projects/isql.html}, } - ICML
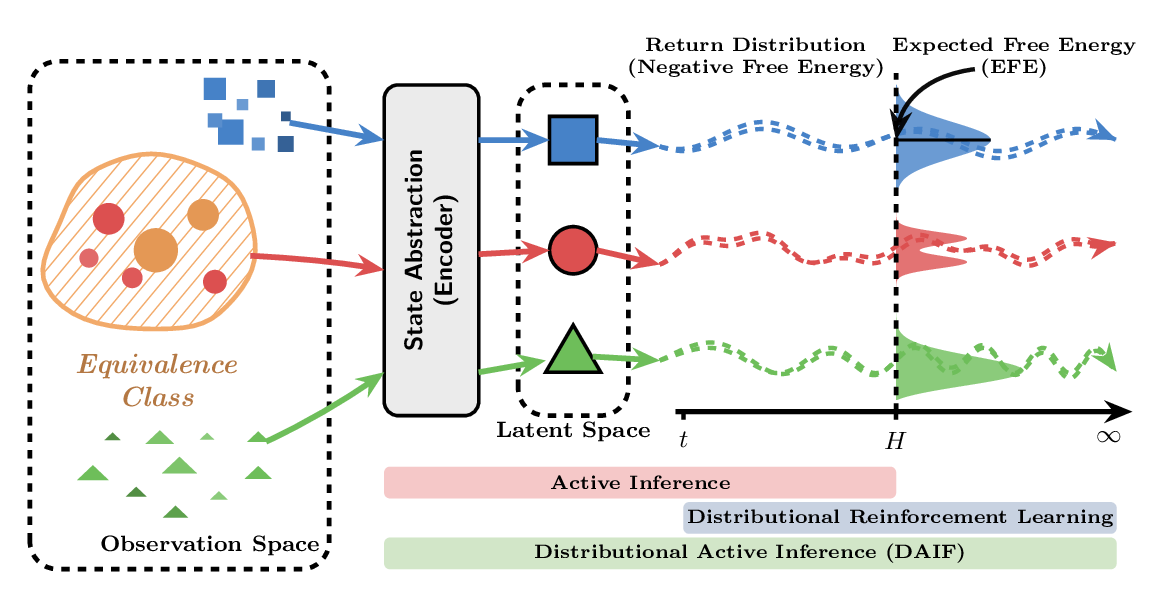 Distributional Active InferenceA. Akgül, G. Baykal, M. Haußmann, M. M. Çelikok, and 1 more authorIn International Conference on Machine Learning, 2026
Distributional Active InferenceA. Akgül, G. Baykal, M. Haußmann, M. M. Çelikok, and 1 more authorIn International Conference on Machine Learning, 2026Optimal control of complex environments with robotic systems faces two complementary and intertwined challenges: efficient organization of sensory state information and far-sighted action planning. Because the reinforcement learning framework addresses only the latter, it tends to deliver sample-inefficient solutions. Active inference is the state-of-the-art process theory that explains how biological brains handle this dual problem. However, its applications to artificial intelligence have thus far been limited to extensions of existing model-based approaches. We present a formal abstraction of reinforcement learning algorithms that spans model-based, distributional, and model-free approaches. This abstraction seamlessly integrates active inference into the distributional reinforcement learning framework, making its performance advantages accessible without transition dynamics modeling.
@inproceedings{akgul2026distributional, title = {Distributional Active Inference}, author = {Akg{\"u}l, A. and Baykal, G. and Hau{\ss}mann, M. and {\c{C}}elikok, M. M. and Kandemir, M.}, year = {2026}, booktitle = {International Conference on Machine Learning}, url = {https://arxiv.org/pdf/2601.20985}, project = {/projects/daif.html}, } - UAIWeighted Sequential Bayesian Inference for Non-Stationary Linear Contextual BanditsN. Werge, Y.S. Wu, A. Akgül, and M. KandemirIn Conference on Uncertainty in Artificial Intelligence, 2026
We study non-stationary linear contextual bandits through the lens of sequential Bayesian inference. Whereas existing algorithms typically rely on the Weighted Regularized Least-Squares (WRLS) objective, we study Weighted Sequential Bayesian (WSB), which maintains a posterior distribution over the time-varying reward parameters. Our main contribution is a novel concentration inequality for WSB posteriors, which introduces a prior-dependent term that quantifies the influence of initial beliefs. We show that this influence decays over time and derive tractable upper bounds that make the result useful for both analysis and algorithm design. Building on WSB, we introduce three algorithms: WSB-LinUCB, WSB-RandLinUCB, and WSB-LinTS. We establish frequentist regret guarantees: WSB-LinUCB matches the best-known WRLS-based guarantees, while WSB-RandLinUCB and WSB-LinTS improve upon them, all while preserving the computational efficiency of WRLS-based algorithms.
@inproceedings{werge2026weighted, title = {Weighted Sequential Bayesian Inference for Non-Stationary Linear Contextual Bandits}, author = {Werge, N. and Wu, Y.S. and Akg{\"u}l, A. and Kandemir, M.}, year = {2026}, booktitle = {Conference on Uncertainty in Artificial Intelligence}, url = {https://arxiv.org/abs/2307.03587}, }



2025
- arXiv
 ObjectRL: An Object-Oriented Reinforcement Learning CodebaseG. Baykal, A. Akgül, M. Haußmann, B. Tasdighi, and 3 more authorsarXiv Preprint, 2025
ObjectRL: An Object-Oriented Reinforcement Learning CodebaseG. Baykal, A. Akgül, M. Haußmann, B. Tasdighi, and 3 more authorsarXiv Preprint, 2025ObjectRL is an open-source Python codebase for deep reinforcement learning (RL), designed for research-oriented prototyping with minimal programming effort. Unlike existing codebases, ObjectRL is built on Object-Oriented Programming (OOP) principles, providing a clear structure that simplifies the implementation, modification, and evaluation of new algorithms. ObjectRL lowers the entry barrier for deep RL research by organizing best practices into explicit, clearly separated components, making them easier to understand and adapt. Each algorithmic component is a class with attributes that describe key RL concepts and methods that intuitively reflect their interactions. The class hierarchy closely follows common ontological relationships, enabling data encapsulation, inheritance, and polymorphism, which are core features of OOP. We demonstrate the efficiency of ObjectRL’s design through representative use cases that highlight its flexibility and suitability for rapid prototyping. The documentation and source code are available at https://objectrl.readthedocs.io and https://github.com/adinlab/objectrl .
@article{baykal2025objectrl, title = {ObjectRL: An Object-Oriented Reinforcement Learning Codebase}, author = {Baykal, G. and Akg{\"u}l, A. and Hau{\ss}mann, M. and Tasdighi, B. and Werge, N. and Wu, Y.S. and Kandemir, M.}, year = {2025}, journal = {arXiv Preprint}, url = {https://arxiv.org/abs/2507.03487}, project = {/projects/objectrl.html}, } - TMLR
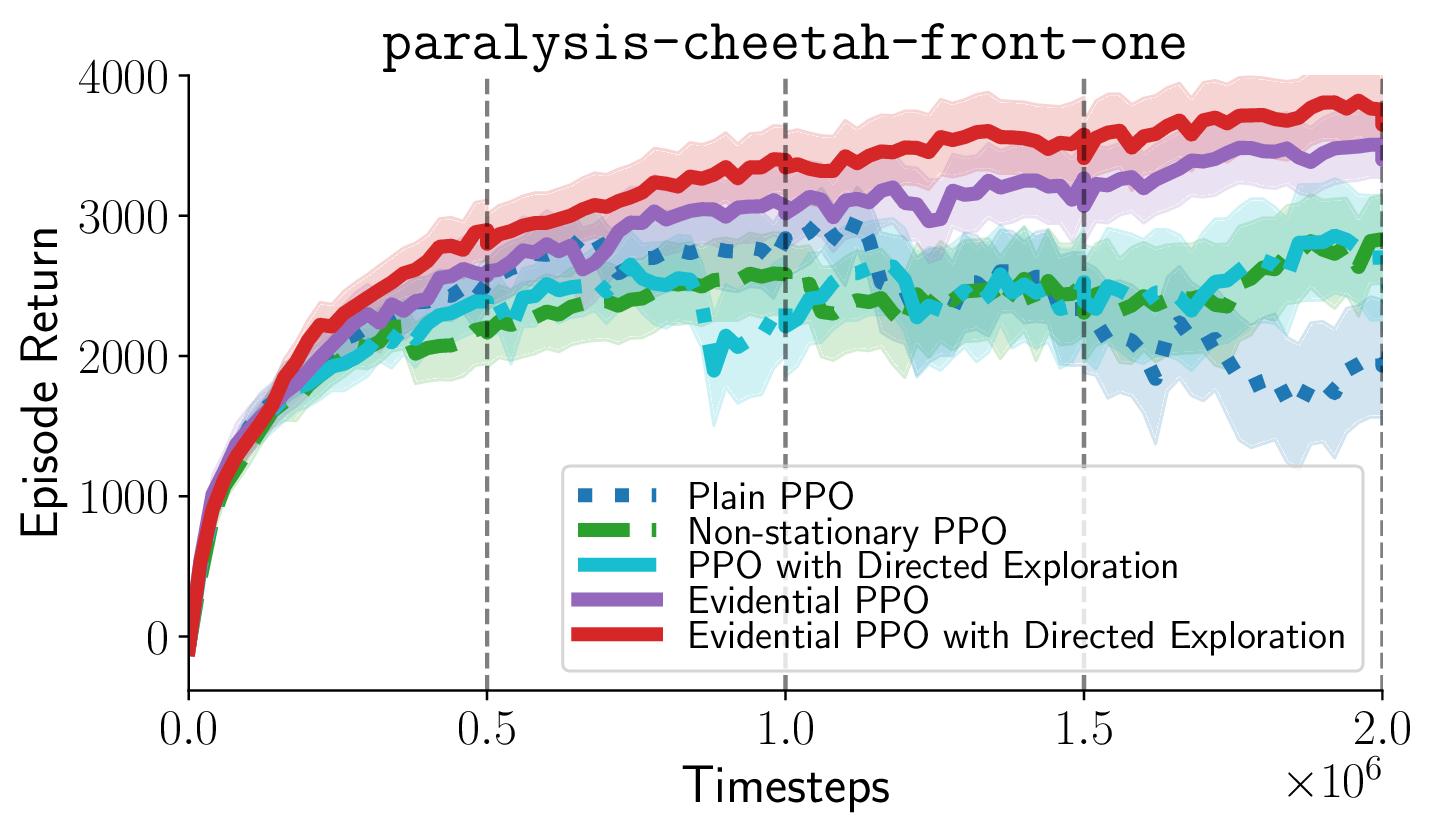 Overcoming Non-stationary Dynamics with Evidential Proximal Policy OptimizationA. Akgül, G. Baykal, M. Haußmann, and M. KandemirTransactions on Machine Learning Research, 2025
Overcoming Non-stationary Dynamics with Evidential Proximal Policy OptimizationA. Akgül, G. Baykal, M. Haußmann, and M. KandemirTransactions on Machine Learning Research, 2025Continuous control of non-stationary environments is a major challenge for deep reinforcement learning algorithms. The time-dependency of the state transition dynamics aggravates the notorious stability problems of model-free deep actor-critic architectures. We posit that two properties will play a key role in overcoming non-stationarity in transition dynamics: (i) preserving the plasticity of the critic network and (ii) directed exploration for rapid adaptation to changing dynamics. We show that performing on-policy reinforcement learning with an evidential critic provides both. The evidential design ensures a fast and accurate approximation of the uncertainty around the state value, which maintains the plasticity of the critic network by detecting the distributional shifts caused by changes in dynamics. The probabilistic critic also makes the actor training objective a random variable, enabling the use of directed exploration approaches as a by-product. We name the resulting algorithm \emphEvidential Proximal Policy Optimization (EPPO) due to the integral role of evidential uncertainty quantification in both policy evaluation and policy improvement stages. Through experiments on non-stationary continuous control tasks, where the environment dynamics change at regular intervals, we demonstrate that our algorithm outperforms state-of-the-art on-policy reinforcement learning variants in both task-specific and overall return.
@article{akgul2025overcoming, title = {Overcoming Non-stationary Dynamics with Evidential Proximal Policy Optimization}, author = {Akg{\"u}l, A. and Baykal, G. and Hau{\ss}mann, M. and Kandemir, M.}, year = {2025}, journal = {Transactions on Machine Learning Research}, url = {https://openreview.net/forum?id=KTfTwxsVNE}, project = {/projects/eppo.html}, type = {article} }


2024
- NeurIPS
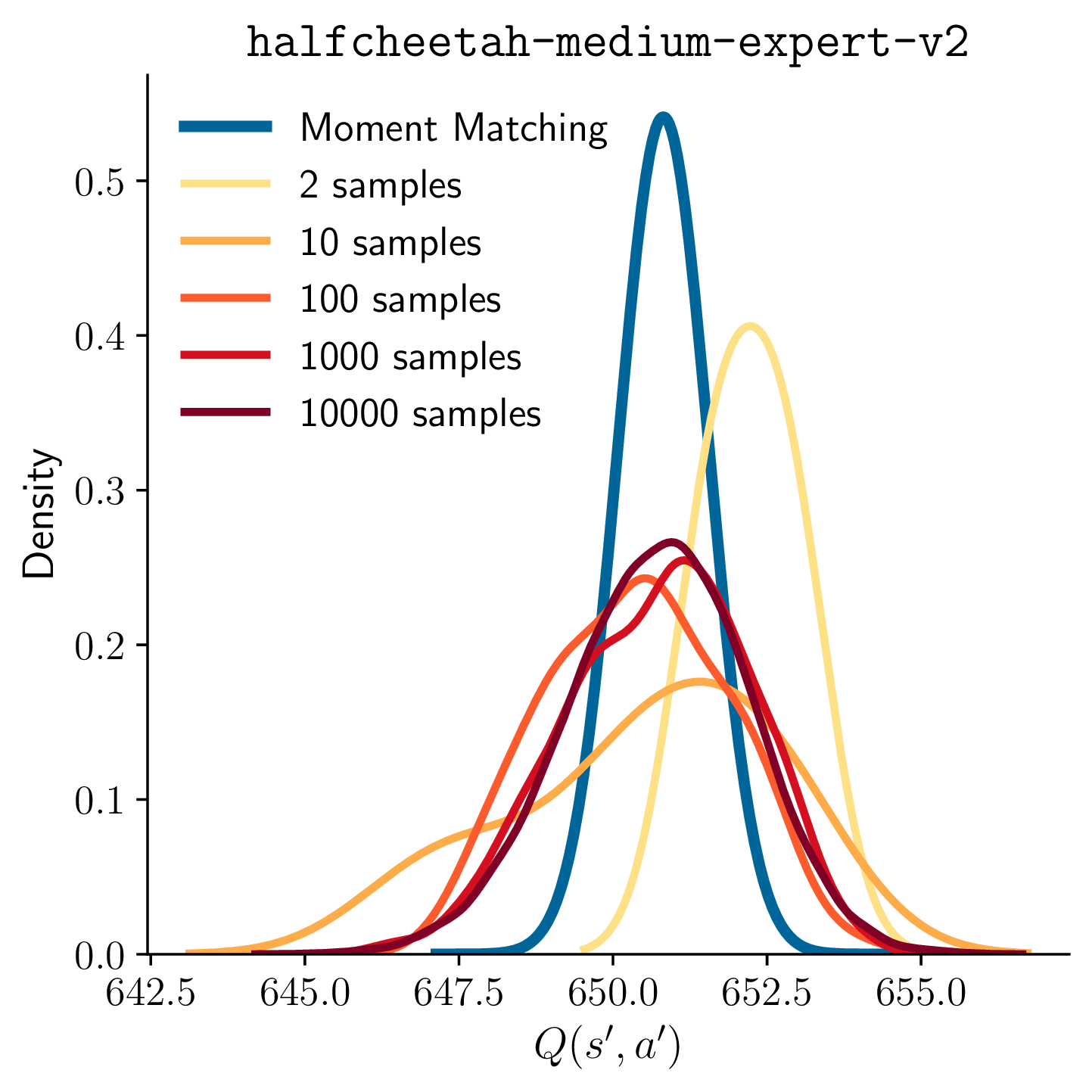 Deterministic Uncertainty Propagation for Improved Model-Based Offline Reinforcement LearningA. Akgül, M. Haußmann, and M. KandemirIn Neural Information Processing Systems, 2024
Deterministic Uncertainty Propagation for Improved Model-Based Offline Reinforcement LearningA. Akgül, M. Haußmann, and M. KandemirIn Neural Information Processing Systems, 2024Current approaches to model-based offline reinforcement learning often incorporate uncertainty-based reward penalization to address the distributional shift problem. These approaches, commonly known as pessimistic value iteration, use Monte Carlo sampling to estimate the Bellman target to perform temporal difference based policy evaluation. We find out that the randomness caused by this sampling step significantly delays convergence. We present a theoretical result demonstrating the strong dependency of suboptimality on the number of Monte Carlo samples taken per Bellman target calculation. Our main contribution is a deterministic approximation to the Bellman target that uses progressive moment matching, a method developed originally for deterministic variational inference. The resulting algorithm, which we call Moment Matching Offline Model-Based Policy Optimization (MOMBO), propagates the uncertainty of the next state through a nonlinear Q-network in a deterministic fashion by approximating the distributions of hidden layer activations by a normal distribution. We show that it is possible to provide tighter guarantees for the suboptimality of MOMBO than the existing Monte Carlo sampling approaches. We also observe MOMBO to converge faster than these approaches in a large set of benchmark tasks.
@inproceedings{akgul2024deterministic, title = {Deterministic Uncertainty Propagation for Improved Model-Based Offline Reinforcement Learning}, author = {Akg{\"u}l, A. and Hau{\ss}mann, M. and Kandemir, M.}, year = {2024}, booktitle = {Neural Information Processing Systems}, url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/82240d93542b74d0c4fdffca39cb779f-Paper-Conference.pdf}, project = {/projects/mombo.html}, } - AABI
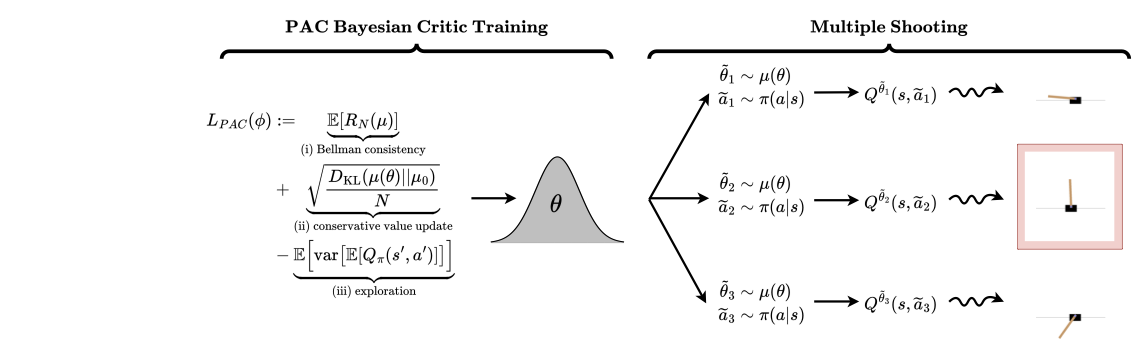 PAC-Bayesian Soft Actor-Critic LearningB. Tasdighi, A. Akgül, M. Haußmann, K.K. Brink, and 1 more authorIn Advances in Approximate Bayesian Inference Symposium, 2024
PAC-Bayesian Soft Actor-Critic LearningB. Tasdighi, A. Akgül, M. Haußmann, K.K. Brink, and 1 more authorIn Advances in Approximate Bayesian Inference Symposium, 2024Actor-critic algorithms address the dual goals of reinforcement learning, policy evaluation and improvement, via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that the online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably to the state of the art on multiple classical control and locomotion tasks in both sample efficiency and asymptotic performance.
@inproceedings{bahareh2024pac4sac, title = {PAC-Bayesian Soft Actor-Critic Learning}, author = {Tasdighi, B. and Akg{\"u}l, A. and Hau{\ss}mann, M. and Brink, K.K. and Kandemir, M.}, year = {2024}, booktitle = {Advances in Approximate Bayesian Inference Symposium}, url = {https://arxiv.org/abs/2301.12776}, project = {/projects/pac4sac.html}, } - ICLRCalibrating Bayesian UNet++ for Sub-Seasonal ForecastingB. Asan, A. Akgül, A. Unal, M. Kandemir, and 1 more authorIn Tackling Climate Change with Machine Learning at ICLR 2024, 2024
Seasonal forecasting is a crucial task when it comes to detecting the extreme heat and colds that occur due to climate change. Confidence in the predictions should be reliable since a small increase in the temperatures in a year has a big impact on the world. Calibration of the neural networks provides a way to ensure our confidence in the predictions. However, calibrating regression models is an under-researched topic, especially in forecasters. We calibrate a UNet++ based architecture, which was shown to outperform physics-based models in temperature anomalies. We show that with a slight trade-off between prediction error and calibration error, it is possible to get more reliable and sharper forecasts. We believe that calibration should be an important part of safety-critical machine learning applications such as weather forecasters.
@inproceedings{asan2024calibrating, title = {Calibrating Bayesian UNet++ for Sub-Seasonal Forecasting}, author = {Asan, B. and Akg{\"u}l, A. and Unal, A. and Kandemir, M. and Unal, G.}, booktitle = {Tackling Climate Change with Machine Learning at ICLR 2024}, year = {2024}, url = {https://arxiv.org/abs/2403.16612}, } - L4DC
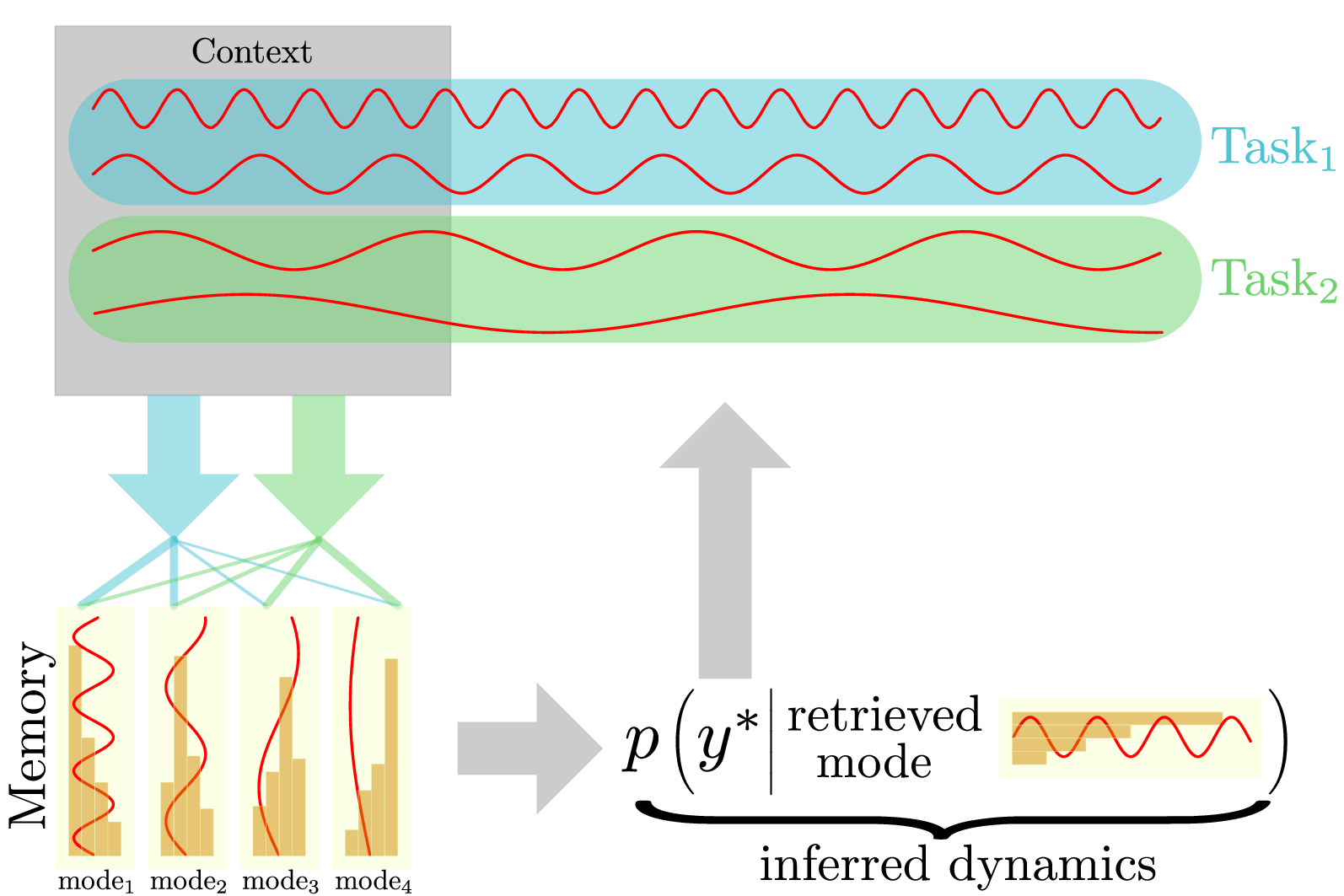 Continual Learning of Multi-modal Dynamics with External MemoryA. Akgül, G. Unal, and M. KandemirIn Proceedings of The 6th Annual Learning for Dynamics and Control Conference, 2024
Continual Learning of Multi-modal Dynamics with External MemoryA. Akgül, G. Unal, and M. KandemirIn Proceedings of The 6th Annual Learning for Dynamics and Control Conference, 2024We study the problem of fitting a model to a dynamical environment when new modes of behavior emerge sequentially. The learning model is aware when a new mode appears, but it does not have access to the true modes of individual training sequences. We devise a novel continual learning method that maintains a descriptor of the mode of an encountered sequence in a neural episodic memory. We employ a Dirichlet Process prior on the attention weights of the memory to foster efficient storage of the mode descriptors. Our method performs continual learning by transferring knowledge across tasks by retrieving the descriptors of similar modes of past tasks to the mode of a current sequence and feeding this descriptor into its transition kernel as control input. We observe the continual learning performance of our method to compare favorably to the mainstream parameter transfer approach.
@inproceedings{akgul2024cddp, title = {Continual Learning of Multi-modal Dynamics with External Memory}, author = {Akg{\"u}l, A. and Unal, G. and Kandemir, M.}, booktitle = {Proceedings of The 6th Annual Learning for Dynamics and Control Conference}, year = {2024}, url = {https://arxiv.org/abs/2203.00936}, project = {/projects/cddp.html}, }



2022
- Master’s Thesis
 Memory-based Approaches to Problems in Probabilistic ModelingA. Akgül2022
Memory-based Approaches to Problems in Probabilistic ModelingA. Akgül2022@article{akgul2022memory, title = {Memory-based Approaches to Problems in Probabilistic Modeling}, author = {Akg{\"u}l, A.}, year = {2022}, publisher = {Lisans{\"u}st{\"u} E{\u{g}}itim Enstit{\"u}s{\"u}}, url = {https://polen.itu.edu.tr/entities/publication/bc96a399-5bdf-493f-aa14-c3143b9ca952}, project = {/projects/mastersthesis.html}, } - ICLR
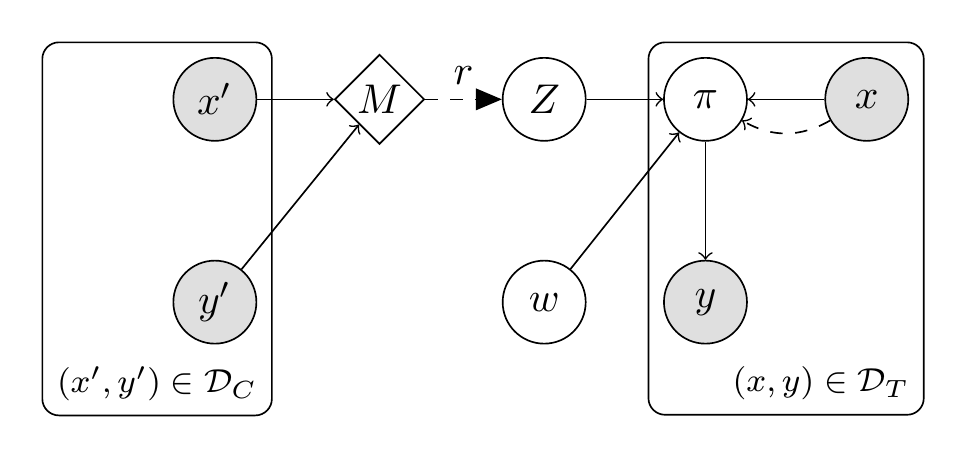 Evidential Turing ProcessesM. Kandemir, A. Akgül, M. Haußmann, and G. UnalIn International Conference on Learning Representations, 2022
Evidential Turing ProcessesM. Kandemir, A. Akgül, M. Haußmann, and G. UnalIn International Conference on Learning Representations, 2022A probabilistic classifier with reliable predictive uncertainties i) fits successfully to the target domain data, ii) provides calibrated class probabilities in difficult regions of the target domain (e.g. class overlap), and iii) accurately identifies queries coming out of the target domain and reject them. We introduce an original combination of Evidential Deep Learning, Neural Processes, and Neural Turing Machines capable of providing all three essential properties mentioned above for total uncertainty quantification. We observe our method on three image classification benchmarks to consistently improve the in-domain uncertainty quantification, out-of-domain detection, and robustness against input perturbations with one single model. Our unified solution delivers an implementation-friendly and computationally efficient recipe for safety clearance and provides intellectual economy to an investigation of algorithmic roots of epistemic awareness in deep neural nets.
@inproceedings{kandemir2022evidential, title = {Evidential Turing Processes }, author = {Kandemir, M. and Akg{\"u}l, A. and Hau{\ss}mann, M. and Unal, G.}, booktitle = {International Conference on Learning Representations}, year = {2022}, url = {https://openreview.net/pdf?id=84NMXTHYe-}, project = {/projects/etp.html}, } - FL-NeurIPS
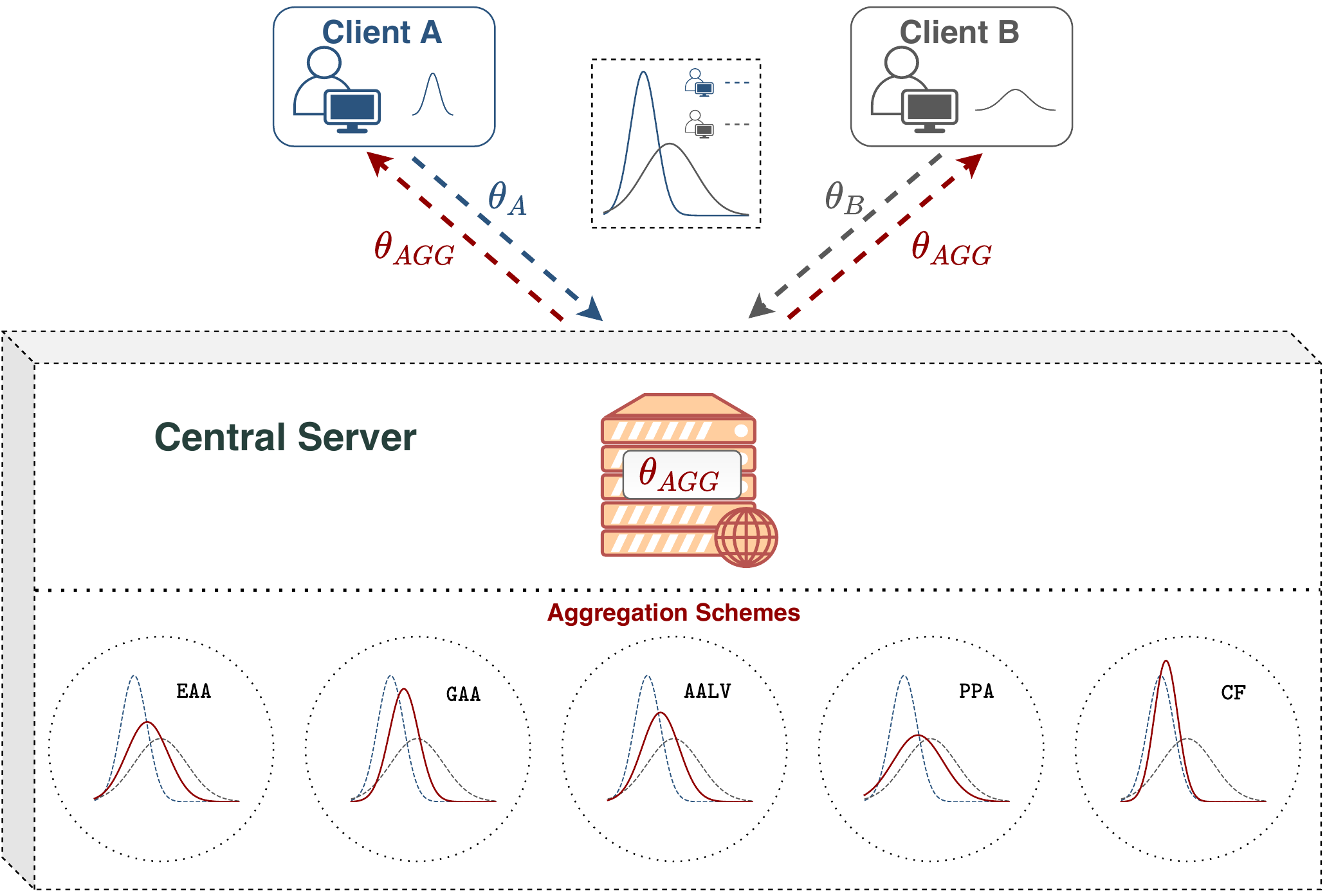 How to Combine Variational Bayesian Networks in Federated LearningA. Ozer, K.B. Buldu, A. Akgül, and G. UnalIn Workshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022
How to Combine Variational Bayesian Networks in Federated LearningA. Ozer, K.B. Buldu, A. Akgül, and G. UnalIn Workshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022Federated Learning enables multiple data centers to train a central model collaboratively without exposing any confidential data. Even though deterministic models are capable of performing high prediction accuracy, their lack of calibration and capability to quantify uncertainty is problematic for safety-critical applications. Different from deterministic models, probabilistic models such as Bayesian neural networks are relatively well-calibrated and able to quantify uncertainty alongside their competitive prediction accuracy. Both of the approaches appear in the federated learning framework; however, the aggregation scheme of deterministic models cannot be directly applied to probabilistic models since weights correspond to distributions instead of point estimates. In this work, we study the effects of various aggregation schemes for variational Bayesian neural networks. With empirical results on three image classification datasets, we observe that the degree of spread for an aggregated distribution is a significant factor in the learning process. Hence, we present an survey on the question of how to combine variational Bayesian networks in federated learning, while providing computer vision classification benchmarks for different aggregation settings.
@inproceedings{ozer2022bfl, title = {How to Combine Variational Bayesian Networks in Federated Learning}, author = {Ozer, A. and Buldu, K.B. and Akg{\"u}l, A. and Unal, G.}, booktitle = {Workshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022)}, year = {2022}, url = {https://openreview.net/forum?id=AkPwb9dvAlP}, project = {/projects/bfl.html}, }


